
推荐系统应用广泛,从播放列表到产品页面均有其应用。然而,与依赖海量数据集的大型语言模型相比,推荐算法的研究往往受限于数据规模,通常只能在小型、过时的数据集上进行评估。
数据集规模与内容
全球科技公司Yandex希望通过发布Yambda-5B数据集来缩小研究与生产之间的差距。这是目前可用于推荐任务的最大规模匿名用户交互数据集。
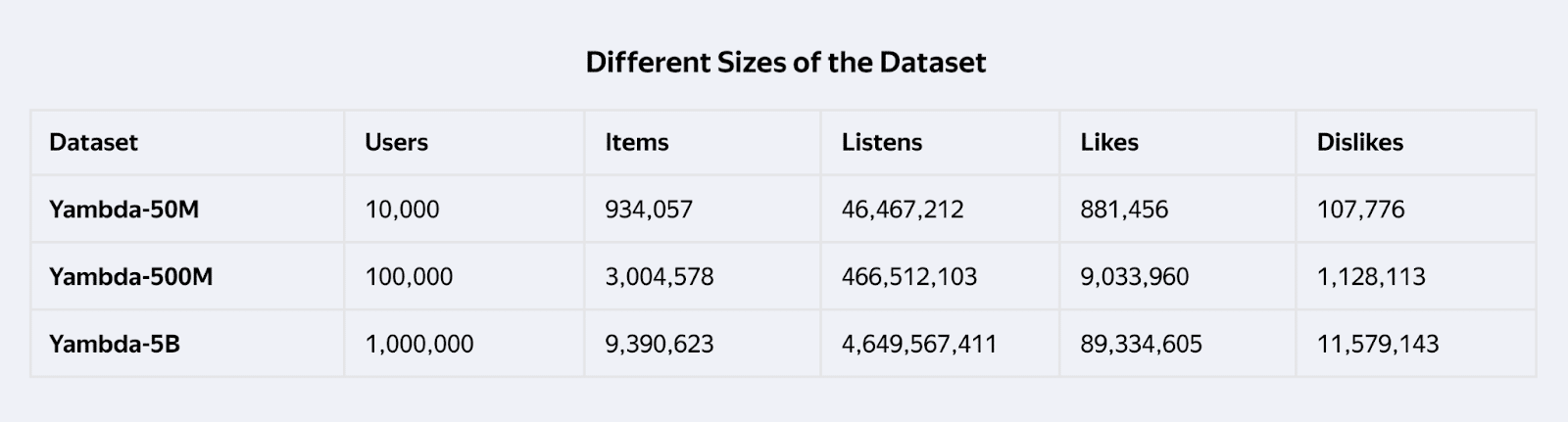
Yambda-5B包含47.9亿条匿名用户交互数据,这些数据来自Yandex音乐(Yandex Music)在10个月期间收集的用户收听、点赞和不喜欢等信息。数据集还包括元数据、音频嵌入、带时间戳的日志,以及一个关键的标记,用于区分用户是通过自然浏览还是算法推荐发现音乐。
数据集特点与优势
Yambda不仅在数据量上更大,其结构设计也更贴近现代使用场景。许多现有的基准数据集难以模拟真实环境的复杂性。例如,经典的Netflix Prize数据集仅包含不到1.8万个项目,且只有日期级别的时间戳,不适合进行时序或序列建模。
相比之下,Yambda包含由卷积神经网络生成的高保真音频嵌入,提供了公共数据集中罕见的内容级特征。它捕捉了五种用户交互类型:收听、点赞、不喜欢、取消点赞和取消不喜欢,使研究人员能够同时研究隐式和显式反馈。
每个事件都有5秒精度的时间戳,用户行为通过"is_organic"标记进行分类,以区分自然发现和推荐驱动的活动。所有用户和音轨身份都使用数字标识符进行匿名化,确保符合隐私标准。
评估方法与应用场景
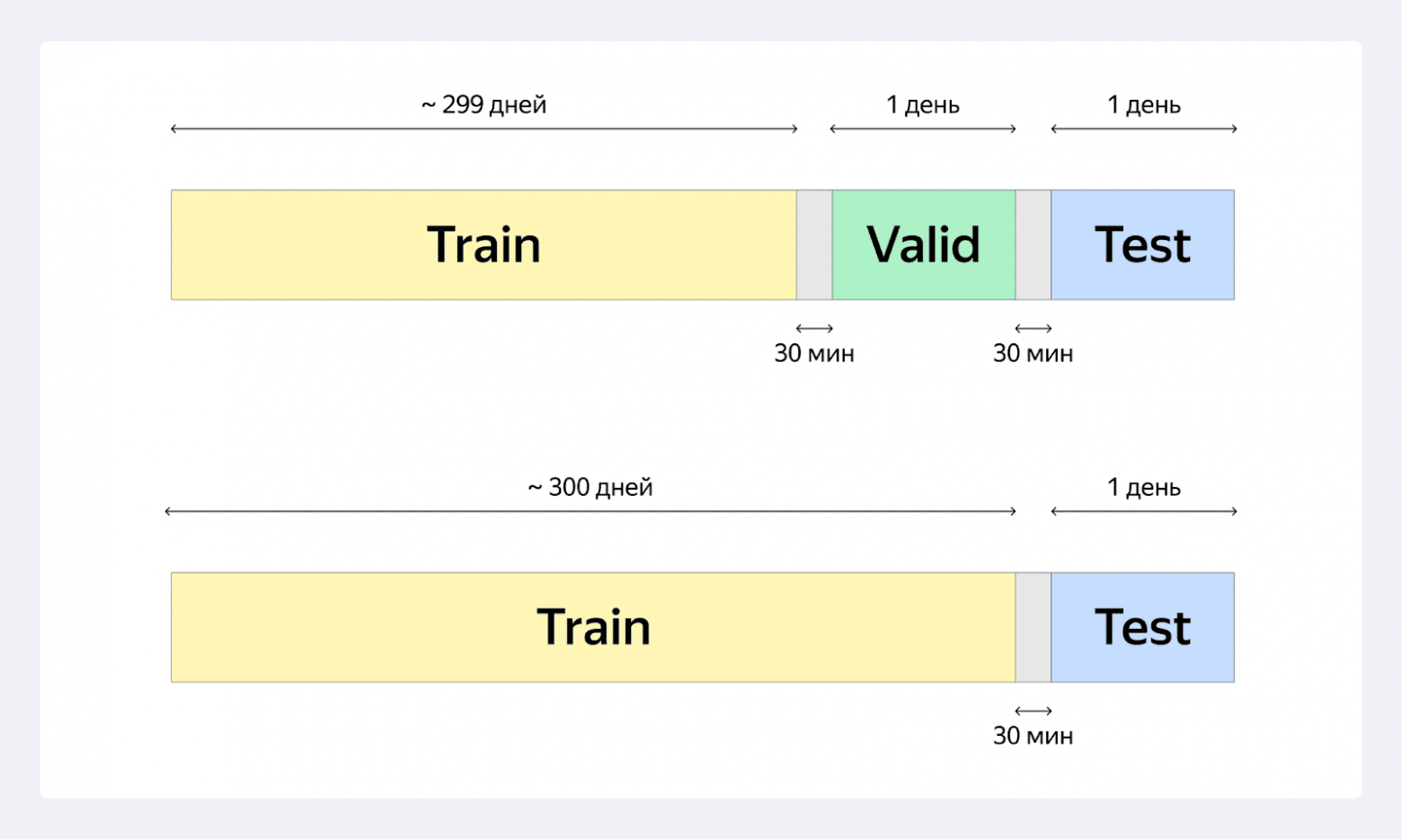
数据集采用全局时间分割(GTS)协议,基于时间而非用户交互模式将数据分为训练集和测试集。这种方法保持了因果一致性,避免了在未来信息上训练模型的常见问题。
在Yambda基准测试中,训练数据跨度为300天,之后是30分钟的缓冲期,然后是一天的测试窗口。研究论文指出:"在训练集和测试集之间设置30分钟的间隔,是为了模拟工业系统中模型训练到部署之间的延迟。"
Yambda配备了完整的基准测试套件,包括传统和现代算法。从简单的基于流行度的方法(如MostPop和DecayPop)到矩阵分解方法(如iALS和BPR),以及擅长捕捉用户行为长期依赖关系的基于Transformer的序列模型SASRec。
开源与影响
所有三种规模的数据集(50M、500M和5B事件)都以Apache Parquet格式在Hugging Face上提供。这使得研究人员无需签署法律协议或获取平台访问权限,就能使用网络规模的训练数据。
值得一提的是,这并非Yandex在AI领域的首次开源项目。该公司此前已发布多个广受机器学习社区欢迎的工具,包括用于识别和评估代码效率的Perforator、用于大型语言模型极限压缩的高级量化算法AQLM、为Transformer架构优化的分片数据并行框架YaFSDP,以及高性能梯度提升决策树库CatBoost。