
核心功能介绍
IBM发布Granite 3.3人工智能模型系列,重点推出语音转文本模型Granite Speech 3.3 8B。该模型在自动语音识别(ASR)和自动语音翻译(AST)领域展现出卓越性能。

技术架构特点
该语音转文本模型基于Granite 3.3 8B Instruct大语言模型开发,同时提供2B参数版本。模型架构包含语音编码器、语音项目、大语言模型和低秩适应(LoRA)适配器,所有模型均以Apache 2.0许可证开源发布。
IBM表示,这是一款紧凑且经济高效的音频输入和文本输出模型,专为企业应用场景设计。在公共数据集测试中,其准确率超过主要开源和闭源竞品,转录任务的错误率也显著降低。
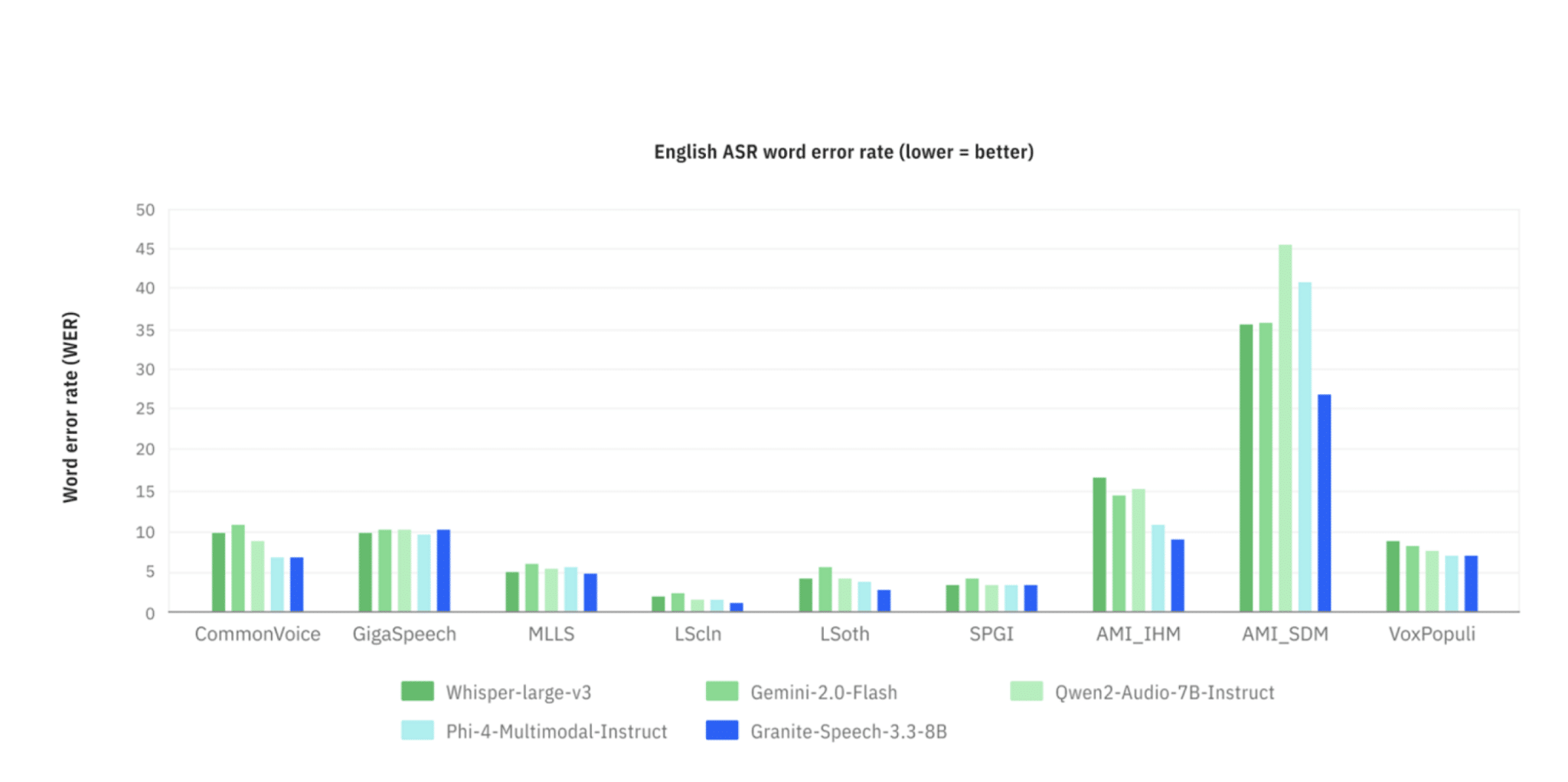
多语言支持能力
模型支持将英语自动翻译为多种语言,包括法语、西班牙语、意大利语、德语、葡萄牙语、日语和普通话。在支持的语言范围内,其性能可与OpenAI的GPT-4和Google的Gemini 2.0 Flash等主流模型相媲美。
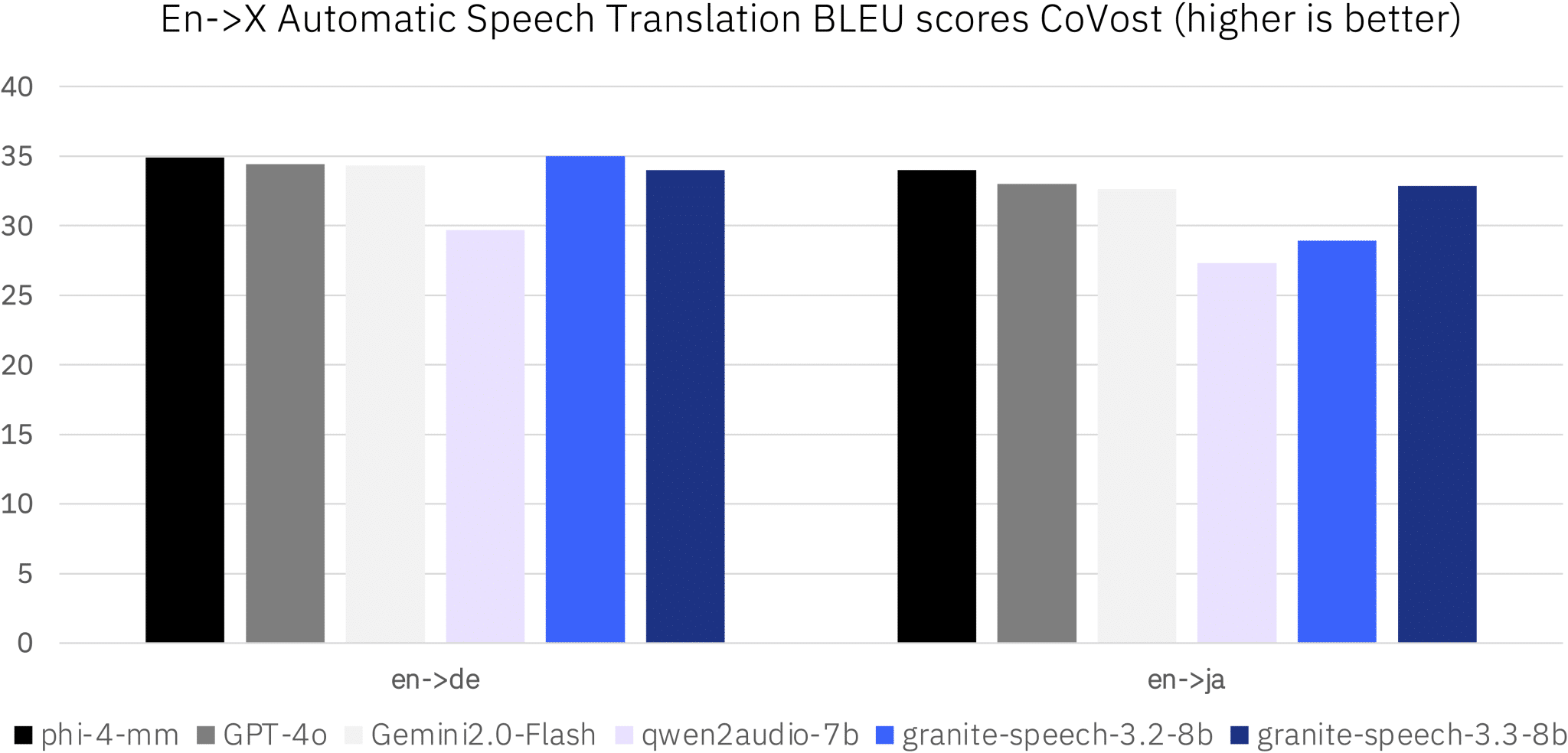
持续优化计划
为提升应用性能,IBM在Hugging Face平台发布了面向检索增强生成的LoRA适配器。目前,该公司正致力于扩展多语言编码支持,并计划通过优化训练数据质量、统一音频特征集成结构等方式提升模型性能。此外,IBM还将开发语音情感识别(SER)功能,并已开始训练新一代Granite 4.0模型,以实现速度、上下文长度和容量的全面提升。