
模型架构与性能
由高瓴资本(High-Flyer Capital Management)支持的中国人工智能研究实验室DeepSeek发布了其前沿模型的最新版本DeepSeek-V3。这个混合专家模型(Mixture-of-Experts)总参数量达到6710亿,每个token激活370亿参数,已在14.8万亿个token上完成训练。DeepSeek已在GitHub上发布了该模型及其详细技术文档。
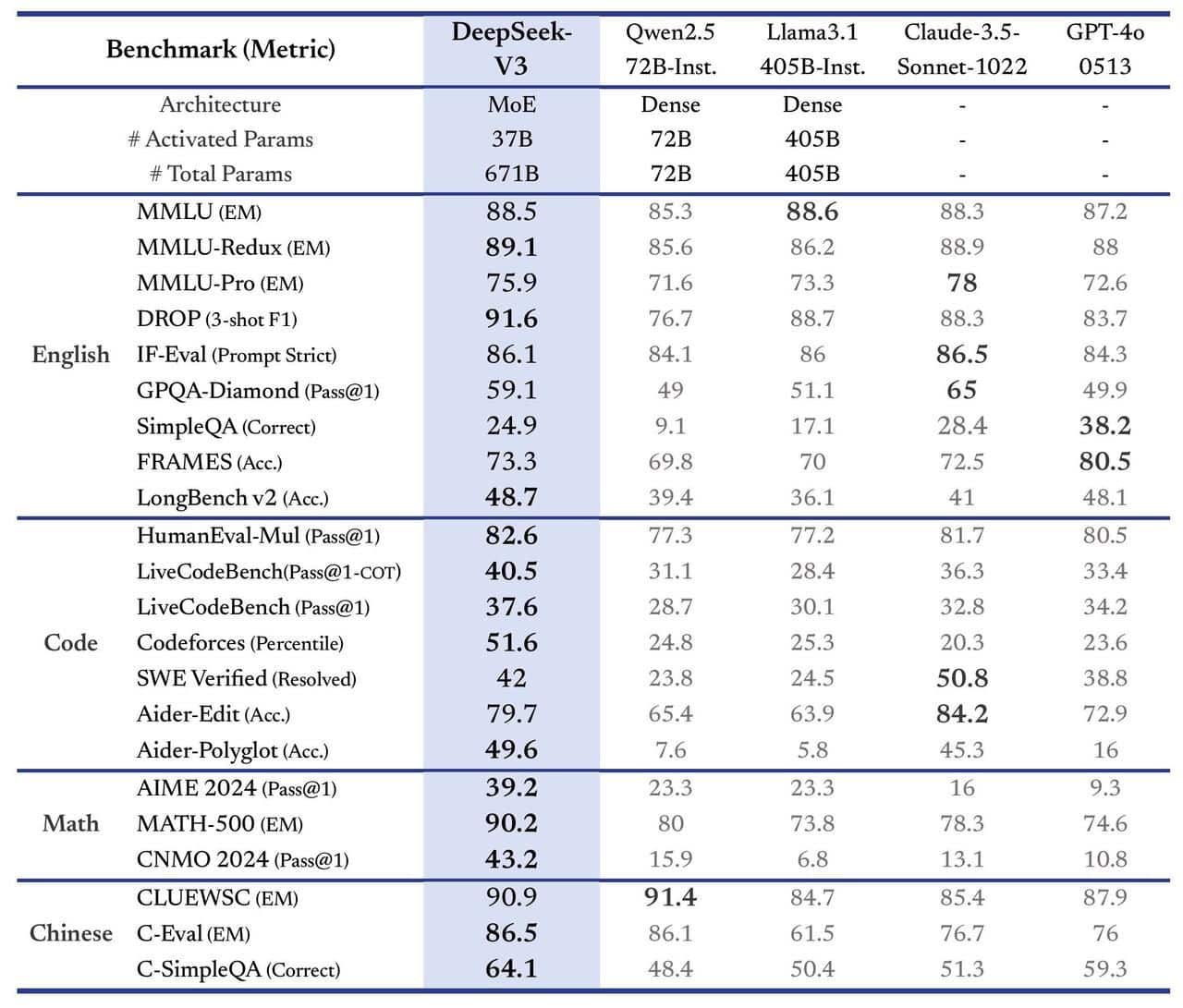
根据基准测试结果,DeepSeek-V3的性能超越了Meta的旗舰产品Llama 3.1(4050亿参数模型)以及多个闭源模型,运行速度较前代产品DeepSeek-V2提升三倍。技术文档显示:"全面评估表明,DeepSeek-V3已成为目前最强大的开源模型,其性能可与GPT-4o和Claude-3.5-Sonnet等领先的闭源模型相媲美。"
技术创新与优化
DeepSeek-V3继承了DeepSeek R1系列模型的推理能力。技术文档指出:"我们的流程将R1的验证和反思模式整合到DeepSeek-V3中,显著提升了其推理性能。"在与OpenAI的o1模型对比中,DeepSeek-V3在GPQA Diamond(博士级科学问题)基准测试中获得59.1%的得分,低于o1的76%。虽然在多个基准测试中落后于o1完整版本,但超越了领先的Claude 3.5 Sonnet。
商业化与竞争格局
在定价策略方面,DeepSeek-V3将在2025年2月8日前维持与V2相同的价格。此后,输入将收取0.27美元/百万token,输出收取1.10美元/百万token。用户可通过chat.deepseek.com访问该模型,开启互联网搜索功能获取实时响应,或通过Hugging Face进行集成。
在开源AI领域,来自中国的模型正在与西方模型展开竞争。继DeepSeek之后,阿里巴巴的通义千问2.5(Qwen 2.5)也展现出与领先模型相当的性能。其中,通义千问2.5-Coder(Qwen2.5-Coder)系列在EvalPlus、LiveCodeBench和BigCodeBench等代码生成基准测试中,达到了与GPT-4o相当的水平。