
技术突破与发布
谷歌最近发布的视频生成模型Veo 3(Veo 3)在互联网上获得广泛关注。该模型凭借出色的性能令业界惊叹,具备音频合成和电影制作工具功能,为AI视频生成领域树立了新标准。
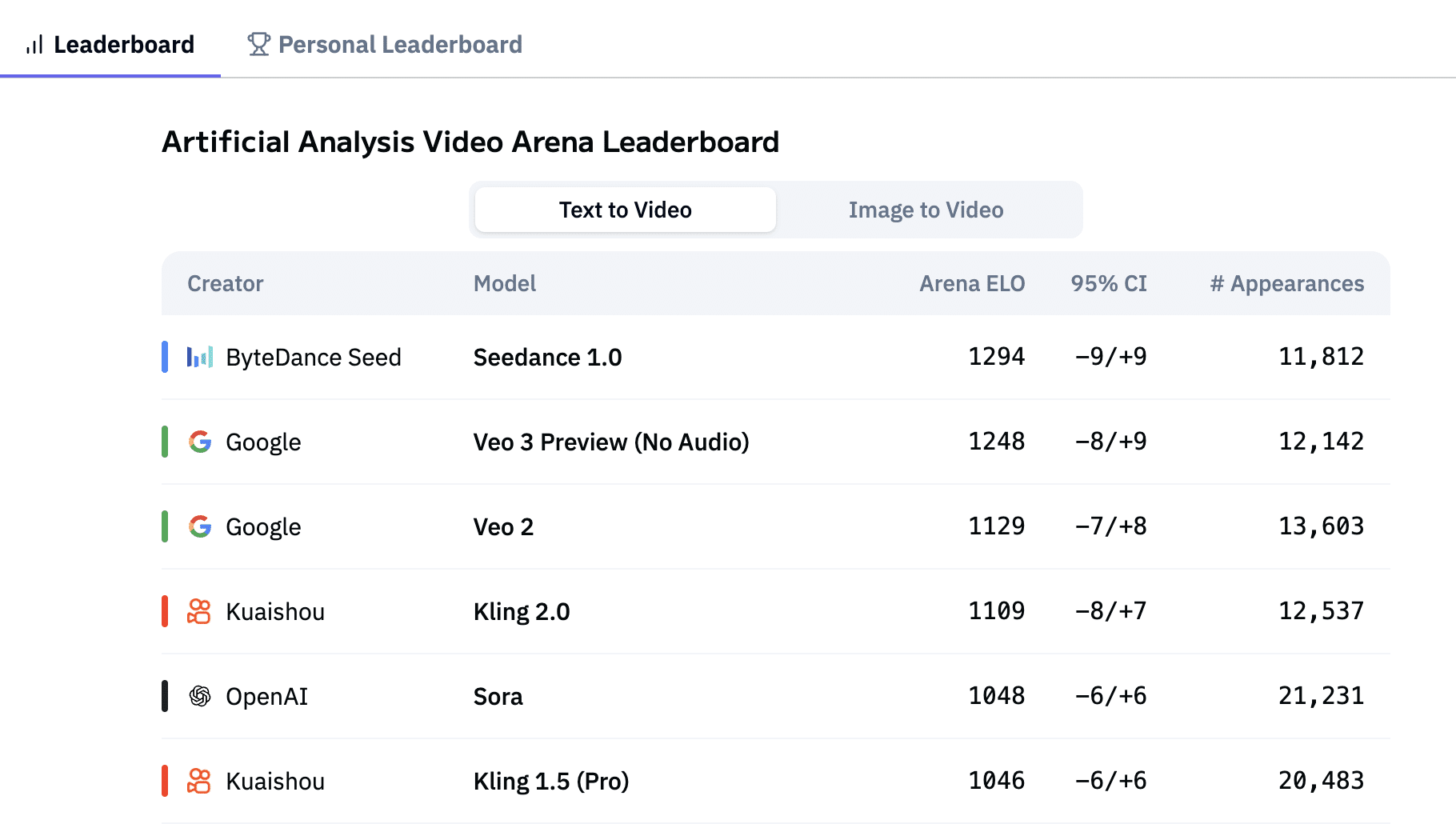
在此背景下,字节跳动发布了双语视频生成模型Seedance 1.0(希丹斯1.0)的研究论文。这款模型目前在文本生成视频和图像生成视频两个领域的独立排行榜上均位居榜首。字节跳动选择以低调的方式发布,仅通过技术基准测试结果展示其实力。

核心技术优势
Seedance 1.0采用创新的交错多模态位置编码技术,实现了空间和时间层的解耦。这使得模型能够在单一架构中同时支持文本生成视频和图像生成视频功能,并原生支持多镜头视频生成。
研发团队构建了一个大规模多源数据集,包含详细的双语字幕和丰富的特征标注。通过优化字幕准确性和采用三重奖励模型的强化学习方案,显著提升了生成效果。

性能对比优势
在SeedVideoBench基准测试中,Seedance 1.0在提示词遵循度和动作真实感方面均优于Veo 3。特别是在图像生成视频任务中,Seedance表现出更强的视觉一致性。
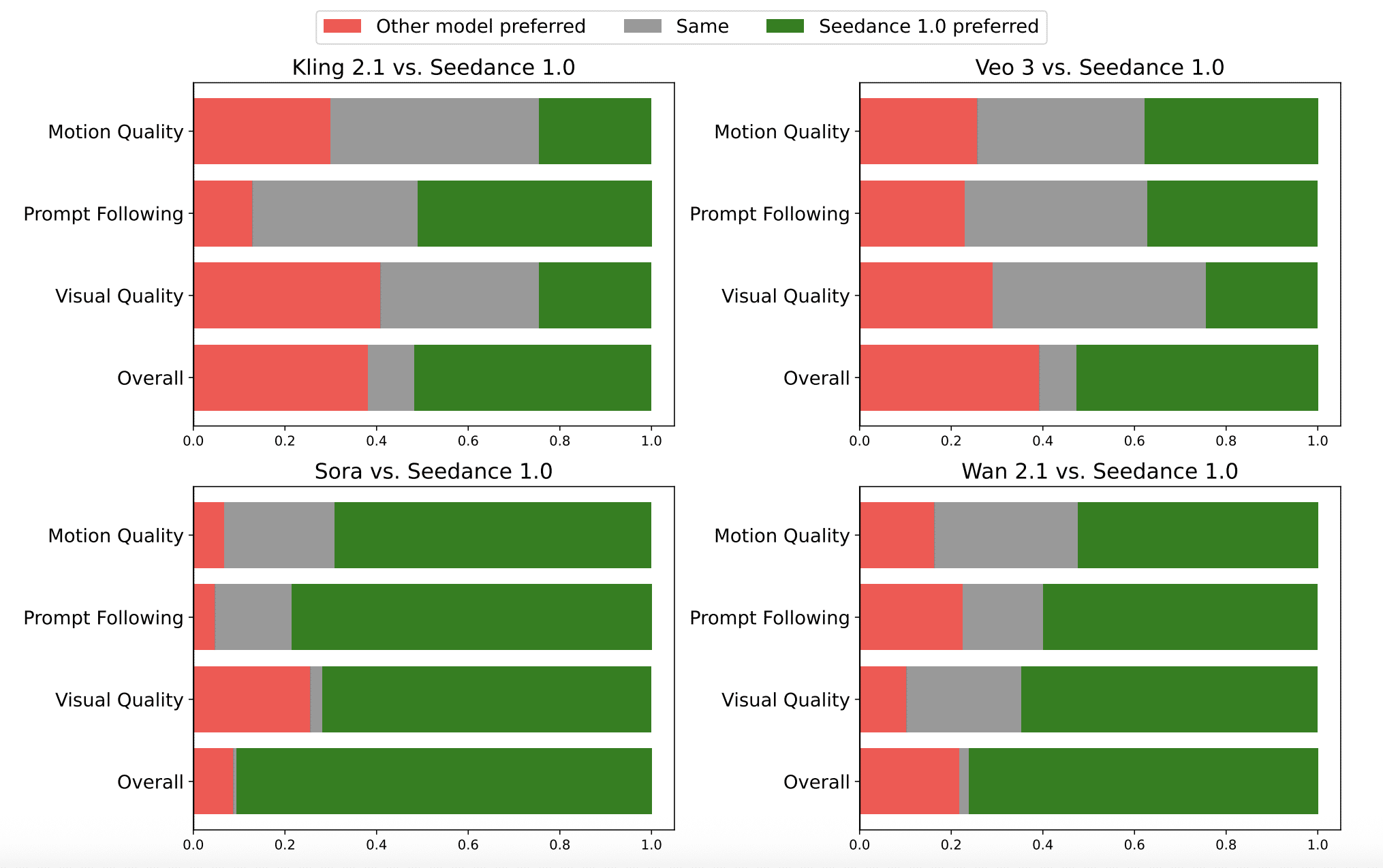
在推理性能方面,Seedance 1.0实现了显著突破。在单个NVIDIA-L20显卡上,生成5秒1080p视频仅需41.4秒,远快于Sora、Runway Gen-4和Veo 3等竞品。这一性能优势为实时视频生成应用提供了可能。
技术特点对比
Veo 3的优势在于音频感知视频合成能力,通过Flow工具提供摄像机移动和镜头构图控制。然而,在视觉对齐和帧一致性方面表现不足,有时会出现主体外观或场景光照变化的问题。
相比之下,Seedance 1.0在视觉连贯性和动作合理性方面表现更为出色,特别适合专业内容创作场景。该模型计划于6月在抖音和剪映等平台集成,有望显著提升创意内容制作效率。
尽管Seedance 1.0暂不支持音频功能,但在视觉质量、动作稳定性和叙事连贯性等核心指标上已经确立了领先优势。