
网站遭遇攻击
周六,Triplegangers公司首席执行官奥列克桑德·托姆丘克(Oleksandr Tomchuk)收到公司电商网站宕机的通知。起初这看似一次分布式拒绝服务攻击(DDoS),但调查显示是OpenAI的爬虫机器人导致了这一问题。
"我们拥有超过65,000件产品,每件产品都有独立页面,每个页面至少包含三张照片。"托姆丘克向TechCrunch表示。OpenAI发送了数万个服务器请求,试图下载所有内容,包括数十万张照片及其详细描述。
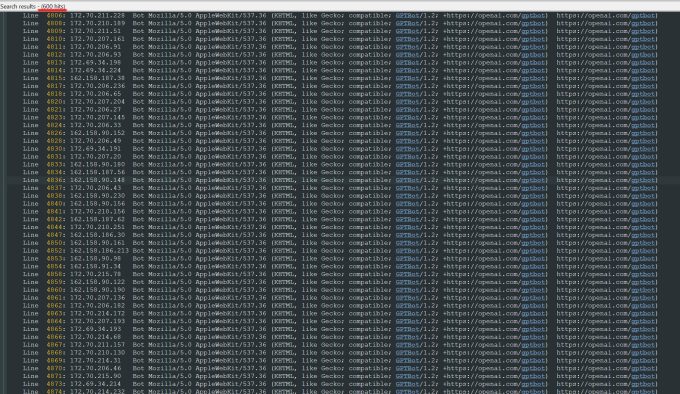
OpenAI使用了600个IP地址进行数据抓取。"我们仍在分析上周的日志,实际数量可能更多,"他说,"他们的爬虫正在压垮我们的网站,这实际上就是一次DDoS攻击。"
公司核心业务受损
Triplegangers是一家仅有七名员工的公司,经过十多年努力建立了全网最大的"人类数字替身"数据库。该数据库包含从真实人体模型扫描获得的3D图像文件。公司主要面向3D艺术家、游戏开发者等客户,提供从手部到头发、皮肤和完整身体等3D文件和照片资源。
该公司总部位于乌克兰,同时在美国佛罗里达州坦帕市注册运营。尽管公司服务条款明确禁止未经授权的机器人抓取,但这种保护形同虚设。网站必须通过正确配置robot.txt文件,并设置特定标签来阻止OpenAI的GPTBot及其他爬虫(如ChatGPT-User和OAI-SearchBot)。
防护措施与持续影响
Robot.txt(机器人排除协议)旨在告知搜索引擎不应抓取的内容。OpenAI称会遵守这些配置,但警告称其机器人可能需要24小时才能识别更新后的robot.txt文件。
到周三,经过多天的应对,Triplegangers完成了robot.txt文件配置,并通过Cloudflare账户阻止了GPTBot等多个爬虫。然而,公司仍无法确认OpenAI已获取的具体内容,也无法要求删除这些数据。OpenAI既未回应TechCrunch的置评请求,也未推出此前承诺的退出工具。
这对Triplegangers构成了特殊挑战。"我们的业务涉及严格的权利问题,因为我们扫描真实的人,"托姆丘克强调,"根据欧洲GDPR等法规,他们不能随意使用网上的任何人的照片。"
托姆丘克提醒其他小型在线企业:"大多数网站都不知道自己被这些机器人抓取了数据。现在我们必须每天监控日志活动来发现这些机器人。这些公司应该先征求许可,而不是直接抓取数据。"