
核心技术创新
微软发布了一款名为Phi-4-mini-flash-reasoning(以下简称Phi-4)的小型AI模型,专门针对设备端的快速逻辑推理进行优化。与上一代产品相比,该模型在吞吐量上提升了10倍,延迟降低了2-3倍,特别适用于移动应用和边缘部署等低延迟环境。
这款开源模型拥有38亿参数,支持64k token的上下文长度,并通过高质量的合成数据针对结构化、数学为主的推理任务进行了微调。Phi-4引入了名为"SambaY"的新型"解码器-混合-解码器"架构,结合了状态空间模型(Mamba)、滑动窗口注意力机制和新型门控记忆单元(Gated Memory Unit,GMU),显著降低了解码复杂度并提升了长上下文性能。
性能优势
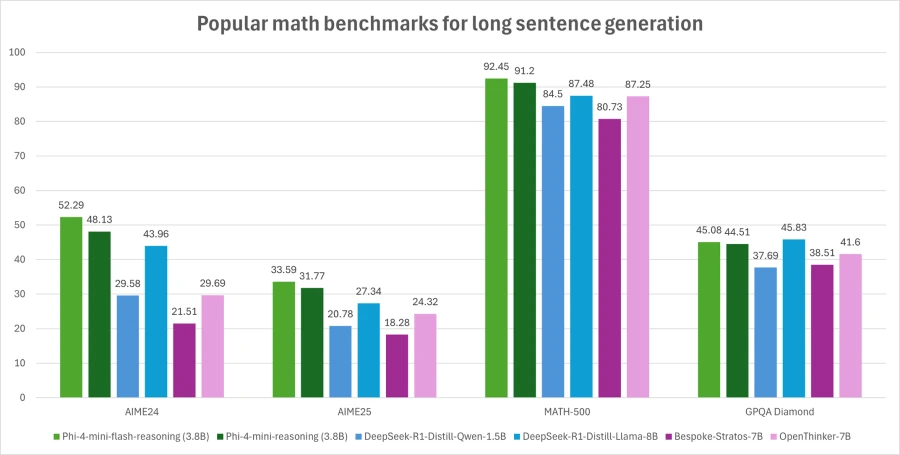
微软表示,新架构允许模型在保持线性预填充计算时间的同时,将轻量级GMU与复杂的注意力层交错使用。基准测试显示,在AIME24/25和Math500等任务上,Phi-4的表现超过了参数量两倍的模型,同时在vLLM推理框架上保持更快的响应速度。
安全部署与应用
该模型采用了完整的安全机制,包括监督微调(SFT)、直接偏好优化(DPO)和基于人类反馈的强化学习(RLHF),符合微软对透明度、隐私和包容性的核心原则。模型已在Azure AI Foundry等平台上线,开发者可通过研究论文和Phi开发指南获取详细技术信息。
行业发展趋势
同期,Hugging Face推出了SmolLM3模型,具备128k tokens的长上下文推理能力和六种语言支持。该模型经过11.2万亿tokens的训练,性能超越了同类3B参数模型,甚至可与4B参数模型相媲美。随着小型语言模型技术的进步,设备端AI应用将获得更优异的性能表现。