
模型概述
字节跳动(ByteDance)——抖音海外版TikTok的母公司近日发布了其最新的图像生成基础模型Seedream 3.0。该模型是一个中英双语模型,旨在解决其前身Seedream 2.0的局限性。

技术创新
模型通过动态采样机制扩大了约100%的数据集规模。在预训练阶段,整合了混合分辨率训练、跨模态RoPE(Rotary Position Embedding,旋转位置编码)、表示对齐损失以及分辨率感知时间步采样等技术,显著提升了可扩展性和视觉语言对齐效果。

在训练优化环节,Seedream 3.0采用多样化的美学标注和基于视觉语言模型(VLM)的奖励机制来提升输出质量。通过一致性噪声期望和重要性感知时间步采样技术,处理速度提升4-8倍,同时保持了图像质量。该模型支持生成最高2K分辨率的图像。
性能对比
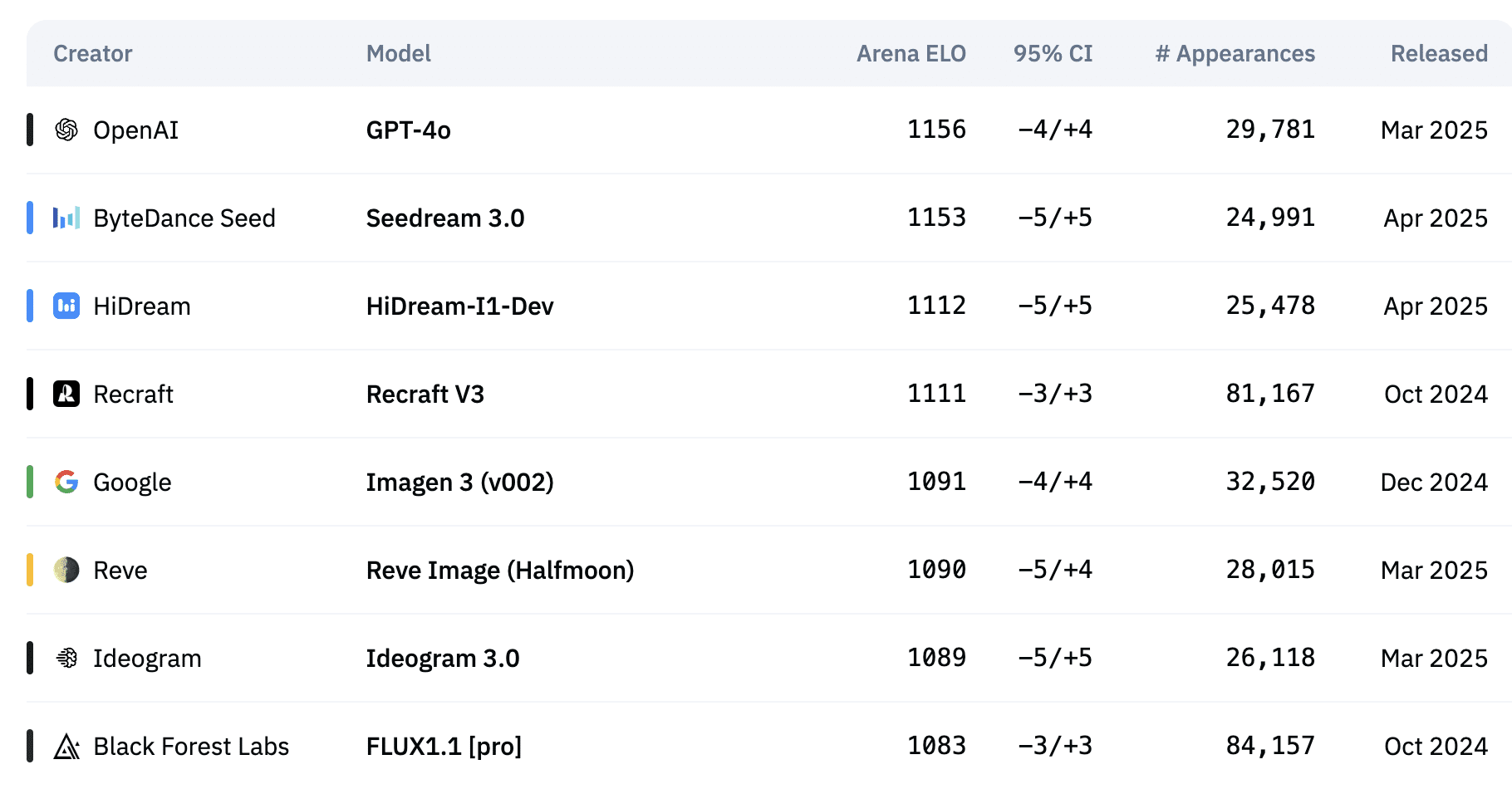
根据人工智能分析平台(Artificial Analysis)的最新基准测试显示,Seedream 3.0的整体表现与OpenAI的GPT-4o相当,并超越了谷歌的Imagen 3。
核心优势
在密集文本渲染领域,Seedream 3.0展现出独特优势,特别是在处理复杂中文文本生成方面,具备优秀的排版和美学构图能力。相比之下,GPT-4o虽然在英文小字符和LaTeX处理方面表现出色,但中文字体处理存在明显局限。
在图像编辑方面,基于Seedream开发的SeedEdit工具在ID保留和提示遵循方面优于GPT-4o和Gemini-2.0,但在复杂编辑场景仍有提升空间。此外,相较于GPT-4o生成的图像常见的暗黄色调和噪点问题,Seedream系列模型在色彩、纹理、清晰度和整体美感方面保持稳定优异的表现。