
新基准测试发布
评估AI模型展现人类智能能力的非营利组织ARC Prize(ARC Prize)发布了ARC-AGI-2基准测试。这是几年前ARC-AGI基准测试的升级版本,专门针对人类容易完成但人工系统难以处理的任务进行评估。新版本不仅考察性能表现,还将每项任务的成本效率纳入评估范围。
测试结果分析
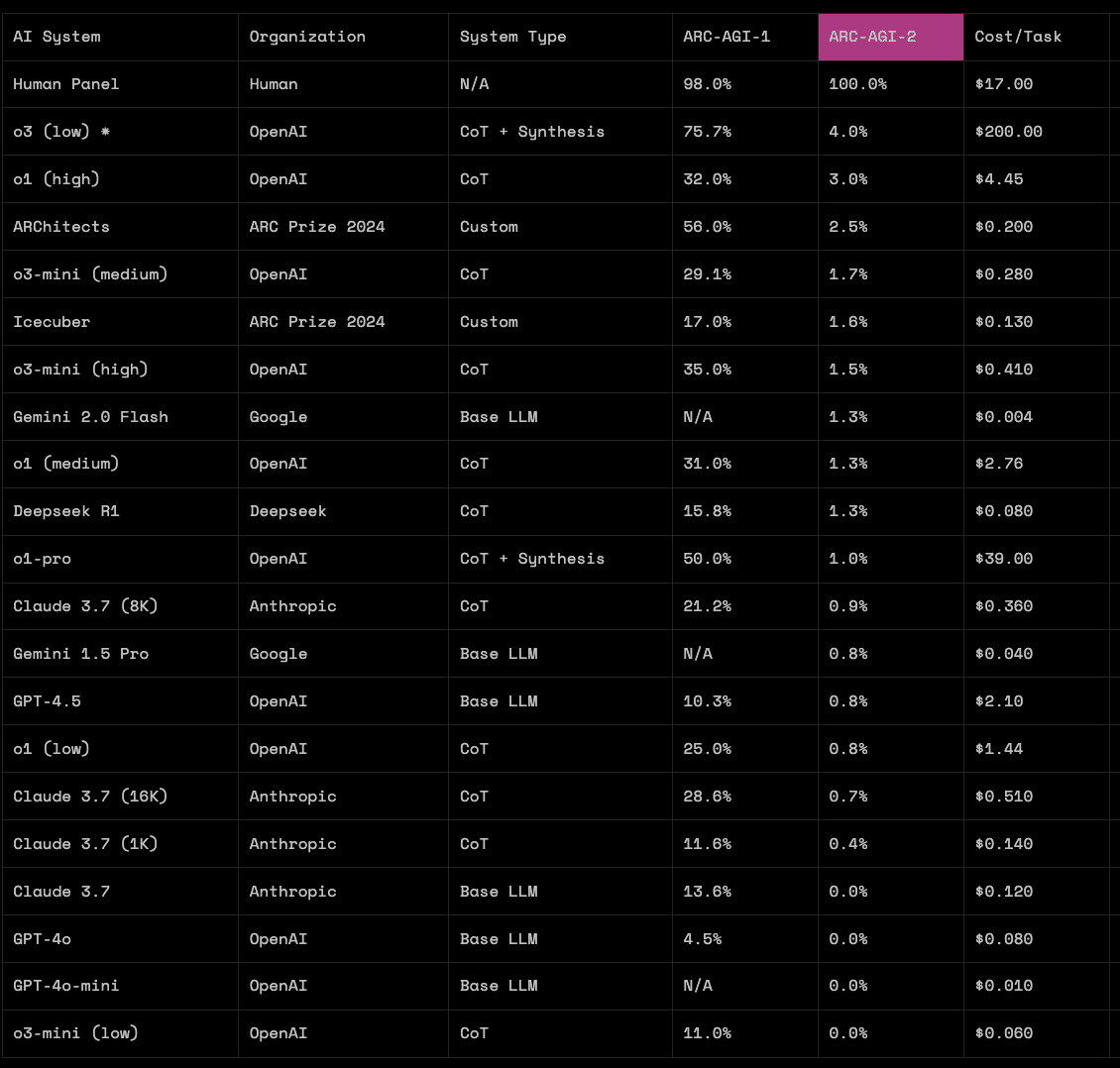
测试要求AI模型完成符号解释、规则关联应用以及上下文相关规则使用等任务。结果显示,非推理模型(纯LLM)得分为0%,其他公开的推理模型得分也未超过4%。相比之下,人类测试组获得了100%的满分。
OpenAI未发布的o3推理模型获得最高分4.0%,远低于其在上一代测试中获得的75.7%。OpenAI首席执行官山姆·奥特曼(Sam Altman)表示,o3的推理能力将整合到混合GPT-5模型中,而不会单独发布。其他知名模型表现同样不佳,编程能力出色的克劳德3.7(Claude 3.7 Sonnet)仅得0.7%,深度探索模型(DeepSeek-R1)得分为1.3%。
专家观点与影响
ARC Prize组织指出,AI系统虽然在围棋和图像识别等特定领域已超越人类,但这些仅是特定领域的专业能力。"人类-AI差距"揭示了AI在高效获取新技能方面的不足,这是实现通用智能的关键。
Keras创始人、前谷歌研究员弗朗索瓦·肖莱(François Chollet)认为,这是"唯一衡量通用智能进展的AI基准测试"。最近,肖莱与Zapier联合创始人迈克·诺普(Mike Knoop)共同创立了致力于开发人工通用智能(AGI)的Ndea研究实验室。